Word Ladder — Coding Interview Walkthrough
You’re in a coding interview. The interviewer says: “Find the shortest transformation sequence from a start word to an end word, changing one letter at a time, using only words from a given word list.” Shortest path means BFS. Each word is a node; two words are connected if they differ by exactly one letter. Word Ladder is LeetCode #127, a graph shortest-path problem in disguise.
This walkthrough covers the BFS approach, the neighbor-generation trick that avoids O(n^2) comparisons, and the bidirectional BFS optimization for follow-up discussions.
The Problem
Given beginWord, endWord, and a wordList, return the number of words in the shortest transformation sequence from beginWord to endWord, where each step changes exactly one letter and the resulting word must be in wordList. Return 0 if no sequence exists. (LeetCode #127)
Example 1
Input
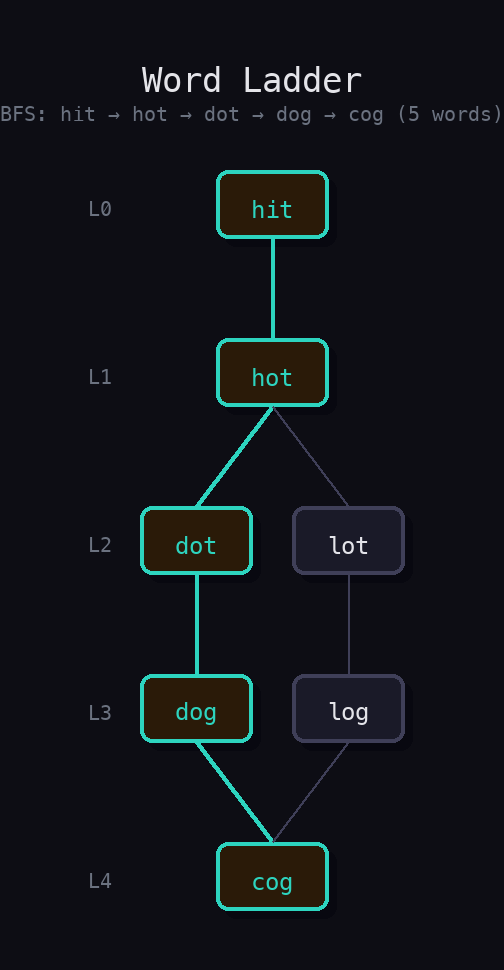
beginWord = "hit", endWord = "cog", wordList = ["hot","dot","dog","lot","log","cog"]
Output
5
Transformation: hit -> hot -> dot -> dog -> cog
Example 2
Input
beginWord = "hit", endWord = "cog", wordList = ["hot","dot","dog","lot","log"]
Output
0 ("cog" is not in the word list)
Already comfortable with the solution? Practice it in a mock interview →
What Interviewers Are Actually Testing
Word Ladder tests whether you recognize a graph problem when it’s not presented as one, and whether you choose BFS (not DFS) for shortest-path finding.
| Skill | What Interviewers Observe |
|---|---|
| BFS for shortest path | Do you use BFS rather than DFS? |
| Word generation | Do you generate neighbors by substituting each position with a-z? |
| Visited set | Do you remove words from the word set to avoid revisiting? |
| Early exit | Do you return as soon as endWord is found? |
| Edge cases | endWord not in wordList, beginWord == endWord? |
Step 1: Clarifying Questions
-
Does
beginWordneed to be inwordList? No.beginWordmay not be in the list. Only intermediate and end words need to be. -
Does
endWordneed to be inwordList? Yes. IfendWordis not inwordList, return0immediately. -
Are all words the same length? Yes, guaranteed by the problem.
-
Is the answer the number of words or the number of transformations? Number of words in the sequence (including
beginWordandendWord). Sohit -> hot -> dot -> dog -> cogis 5, not 4.
Step 2: A First (Non-Optimal) Idea
For each word in the BFS queue, compare it against every word in the word list to find neighbors (words differing by exactly one character). This is O(n * L) per node, giving O(n^2 * L) total, where n is the word list size and L is the word length.
| Approach | Time | Space |
|---|---|---|
| Compare every pair | O(n^2 * L) | O(n * L) |
| Generate 26*L candidates | O(n * L * 26) = O(n * L^2) | O(n * L) |
When n >> L (large dictionaries, short words), generating candidates by substituting each position with a-z is much faster.
Step 3: The Key Insight
BFS from
beginWord. For each word in the queue, generate all one-letter variations by substituting each character position with a-z. If a variation is in the word set, add it to the queue and remove it from the set. Return the level count whenendWordis reached.
Removing words from the set on enqueue (not on dequeue) prevents duplicates. This is equivalent to a visited set but uses the word set itself.
 ---
---
Step 4: Optimal Strategy
- Convert
wordListto a set for O(1) lookups. - Check if
endWordis in the set. If not, return 0. - Initialize a BFS queue with
(beginWord, 1). - For each word in the queue:
- For each character position, try all 26 lowercase letters.
- If the resulting word equals
endWord, returnlength + 1. - If the resulting word is in the word set, add it to the queue and remove it from the set.
- If the queue empties without finding
endWord, return 0.
Python Implementation
from collections import deque
def ladderLength(beginWord: str, endWord: str, wordList: list[str]) -> int:
word_set = set(wordList)
if endWord not in word_set:
return 0
queue = deque([(beginWord, 1)])
visited = {beginWord}
while queue:
word, length = queue.popleft()
for i in range(len(word)):
for c in 'abcdefghijklmnopqrstuvwxyz':
next_word = word[:i] + c + word[i+1:]
if next_word == endWord:
return length + 1
if next_word in word_set and next_word not in visited:
visited.add(next_word)
queue.append((next_word, length + 1))
return 0Why this is interview-friendly:
- Set-based lookup is O(1). Converting the word list to a set is the key optimization.
- Early return on
endWord. No need to process the entire level. visitedprevents revisiting. Adding tovisitedon enqueue (not dequeue) prevents duplicates from entering the queue.
Follow-up: Bidirectional BFS. BFS from both beginWord and endWord simultaneously. When the two frontiers meet, return the combined length. This reduces the search space from O(b^d) to O(b^(d/2)), a significant speedup for large dictionaries.
Time & Space Complexity
| Time | Space | |
|---|---|---|
| BFS | O(M^2 * N) | O(M * N) |
M = word length, N = number of words. For each word, we generate M * 26 candidates. Each candidate construction is O(M) for string slicing.
Common Interview Mistakes
-
Using DFS instead of BFS. DFS finds a path but not the shortest path. BFS guarantees shortest path in an unweighted graph.
-
Not removing words from the set after visiting. Without this, BFS can revisit words, creating cycles and infinite loops. Mark words as visited when they’re enqueued, not when they’re dequeued.
-
Not checking
endWord in wordListupfront. IfendWordisn’t in the word list, no path exists. Return 0 immediately instead of running the full BFS. -
Comparing every word in the list to find neighbors. O(n * L) per BFS node. Generating 26 * L candidates and checking the set is faster for large word lists.
What a Strong Candidate Sounds Like
“This is a shortest-path problem, so BFS is the right tool. Each word is a node; two words are connected if they differ by one letter. I generate neighbors by substituting each position with a-z and checking the word set. I remove words from the set as I enqueue them to prevent revisiting. Return the level count when I hit
endWord. For a follow-up optimization, bidirectional BFS cuts the search space significantly.”
Example Interview Dialogue
Interviewer: Why not check every word in the list against the current word to find neighbors?
Candidate: That’s O(N * L) per node, giving O(N^2 * L) total where N is the word list size. Generating candidates by substituting each position with a-z is O(26 * L^2) per node (26 letters times L positions times L for string construction), which is much faster when N >> L, the common case for dictionary-sized word lists.
Interviewer: What if there are multiple shortest paths?
Candidate: BFS finds the length of the shortest path, but not all paths. To find all shortest transformation sequences (Word Ladder II, LeetCode #126), you’d track all parents of each node during BFS, then backtrack from endWord to beginWord to enumerate all shortest paths.
Related Problems
- Word Ladder II (LeetCode #126). Find all shortest transformation sequences, BFS + backtracking.
- Minimum Genetic Mutation (LeetCode #433). Same BFS shortest-path pattern on gene strings.
- Open the Lock (LeetCode #752). BFS on a state space with constrained transformations.
- Number of Islands (LeetCode #200). BFS/DFS graph traversal on a grid, a simpler version of the same pattern.
Practice This in a Mock Interview
Word Ladder trains you to recognize graph problems in non-graph disguise. If you see “shortest transformation sequence,” think BFS immediately. The neighbor-generation trick (substitute each position with a-z) is the implementation detail that makes it efficient, and the detail most candidates get wrong under time pressure.
Start a mock interview for Word Ladder on Intervu.
Further reading:
- How to Prepare for a Coding Interview in 2026, the complete roadmap and study plans
- Why LeetCode alone isn’t enough, and what to practice instead
- Practice any LeetCode problem as a live mock interview
- The Grind 75 Pathway, a structured study plan with AI practice links
- Browse all walkthroughs on GitHub, condensed solutions with code