LRU Cache — Coding Interview Walkthrough

You’re in a coding interview. The interviewer says: “Design an LRU cache that supports get and put in O(1) time.” You know the answer involves a hash map and a doubly linked list. But now you need to explain why each is necessary, derive the coupling between them from first principles, implement four-pointer insert and remove operations without bugs, and handle the eviction case cleanly while someone watches every line you write.
This walkthrough builds the full LRU Cache explanation from scratch: from the naive approach to the optimal hash map + doubly linked list design, with every pointer operation spelled out and every common implementation mistake named.
The Problem
Design a data structure that implements a Least Recently Used (LRU) cache with a fixed capacity. It must support two operations, both in O(1) time: (LeetCode #146)
get(key)— Return the value associated withkeyif it exists in the cache. Otherwise return-1. Accessing a key counts as “using” it and moves it to the most recently used position.put(key, value)— Insert or update the value forkey. If inserting would exceed capacity, evict the least recently used key first.
Example
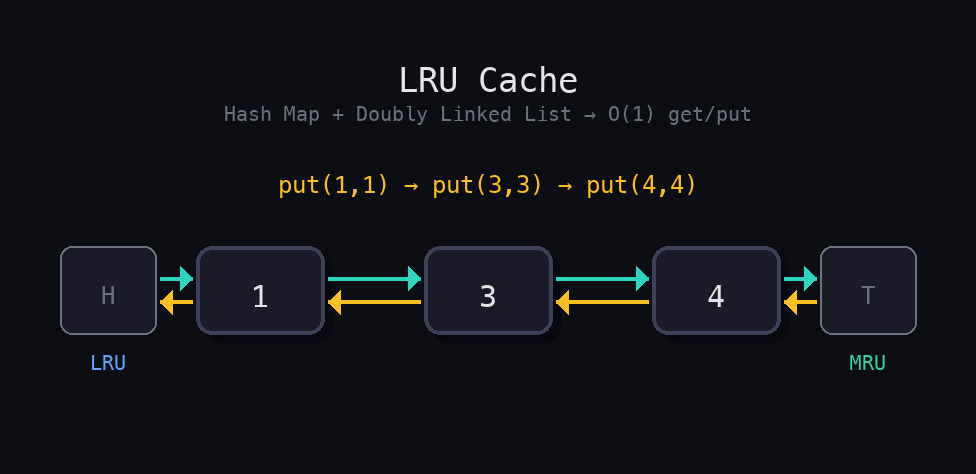
Input
["LRUCache", "put", "put", "get", "put", "get", "put", "get", "get", "get", "medium"]
[[2], [1,1], [2,2], [1], [3,3], [2], [4,4], [1], [3], [4], "medium"]Output
[null, null, null, 1, null, -1, null, -1, 3, 4]
The cache has capacity 2. After inserting keys 1 and 2, a get(1) returns 1 and marks key 1 as most recently used. Inserting key 3 evicts key 2 (now least recently used). A subsequent get(2) returns -1 because it was evicted. Inserting key 4 evicts key 1. The final get(3) and get(4) return 3 and 4 respectively.
Already comfortable with the solution? Practice it in a mock interview →
What Interviewers Are Actually Testing
LRU Cache is a data structure design problem. Interviewers aren’t just checking if you know the answer. They’re watching whether you can reason from requirements to design decisions, build a non-trivial data structure precisely, and maintain complex pointer state without bugs.
| Skill | What Interviewers Observe |
|---|---|
| Requirements-to-design thinking | Do you derive the need for O(1) lookup AND O(1) ordering from the constraints? |
| Data structure selection | Do you independently identify that hash map + doubly linked list is the right combination? |
| Pointer manipulation precision | Can you implement insert, remove, and move_to_front without pointer bugs? |
| Sentinel node insight | Do you use dummy head/tail nodes to eliminate edge cases, or struggle with null checks? |
| Design articulation | Can you explain why each data structure is needed before writing a line of code? |
| Follow-up readiness | Can you extend to LFU cache, thread-safe LRU, or distributed LRU? |
Step 1: Clarifying Questions
LRU Cache rewards candidates who think about requirements before designing. These questions shape the entire implementation:
-
What should
getreturn for a key that doesn’t exist? The problem specifies-1. Confirming this determines your return type and eliminates ambiguity in thegetimplementation. -
What happens if
putis called with a key that already exists? It should update the value and move the key to most recently used. An update counts as a “use.” Missing this causes subtle correctness bugs. -
Is capacity guaranteed to be at least 1? Yes, per LeetCode constraints. If
capacity = 0were possible, everyputwould immediately evict, a degenerate case worth acknowledging. -
Do
getandputneed to be thread-safe? Not for this problem, but asking demonstrates systems awareness. If thread safety were required, you’d need a mutex around each operation. -
Should
puton an existing key count as a recency update even if the value doesn’t change? Yes. Anyputcall on an existing key should move it to most recently used. This unifies the update and insert cases.
Step 2: A First (Non-Optimal) Idea
The most natural first attempt is to use an ordered list alongside a dictionary. The dictionary maps keys to values for O(1) lookup. The list tracks insertion order to determine which key is least recently used.
class LRUCache:
def __init__(self, capacity):
self.capacity = capacity
self.cache = {} # key -> value
self.order = [] # tracks recency, oldest at index 0
def get(self, key):
if key not in self.cache:
return -1
self.order.remove(key) # O(n) — scan the list to find the key
self.order.append(key) # Move to most recently used
return self.cache[key, "medium"]
def put(self, key, value):
if key in self.cache:
self.order.remove(key) # O(n)
elif len(self.cache) >= self.capacity:
lru_key = self.order.pop(0) # O(n) — shifting the entire list
del self.cache[lru_key, "medium"]
self.cache[key] = value
self.order.append(key)This is correct but O(n) per operation due to list.remove() (linear scan) and list.pop(0) (linear shift). The problem explicitly demands O(1) for both operations.
| Approach | get | put | Space |
|---|---|---|---|
| List + dict (naive) | O(n) | O(n) | O(capacity) |
| Hash map + doubly linked list | O(1) | O(1) | O(capacity) |
Step 3: The Key Insight
Couple a hash map (for O(1) lookup) with a doubly linked list (for O(1) reordering). The hash map stores key-to-node references so you can jump directly to any node and move it to the front without searching.
Here’s the chain of reasoning:
O(1) lookup requires a hash map. A dictionary maps keys to their associated data in O(1).
O(1) recency tracking requires a doubly linked list. A linked list lets you move a node to the front in O(1), as long as you already have a pointer to that node. Removal from the middle of a doubly linked list is O(1) when you hold the node reference.
The two structures must be coupled. The hash map stores not just values, but node references into the linked list. When get(key) is called, you jump directly to the node in O(1) and move it to the front.
Sentinel (dummy) head and tail nodes eliminate edge cases. Without them, every insertion and deletion requires checking “is this the first/last node?” With dummy nodes at both ends, the real nodes always live between head.next and tail.prev. This removes four or five conditional branches from your implementation.
Step 4: Optimal Strategy
Here’s the complete algorithm, step by step:
- Define a
Nodeclass withkey,value,prev, andnextfields. - In
__init__, create dummyheadandtailnodes and link them:head.next = tail,tail.prev = head. - Initialize an empty hash map
cache = {}mapping keys to their nodes. - Implement a private
_remove(node)helper that unlinks a node from its neighbors in O(1). - Implement a private
_insert_at_front(node)helper that places a node just after the dummyheadin O(1). - For
get(key): if not in cache, return-1. Otherwise remove and reinsert the node at front, returnnode.value. - For
put(key, value): if key exists, remove old node. If at capacity, evicttail.prev. Create new node, insert at front, add to map.
Python Implementation
class Node:
"""Doubly linked list node storing key, value, and neighbor pointers."""
def __init__(self, key=0, value=0):
self.key = key
self.value = value
self.prev = None
self.next = None
class LRUCache:
def __init__(self, capacity: int):
self.capacity = capacity
self.cache = {} # key -> Node
# Sentinel nodes eliminate null-pointer edge cases at list boundaries
self.head = Node() # Dummy head — most recently used side
self.tail = Node() # Dummy tail — least recently used side
self.head.next = self.tail
self.tail.prev = self.head
def _remove(self, node: Node) -> None:
"""Unlink a node from its current position in the list. O(1)."""
prev_node = node.prev
next_node = node.next
prev_node.next = next_node
next_node.prev = prev_node
def _insert_at_front(self, node: Node) -> None:
"""Insert a node immediately after the dummy head (most recent). O(1)."""
node.prev = self.head
node.next = self.head.next
self.head.next.prev = node
self.head.next = node
def get(self, key: int) -> int:
if key not in self.cache:
return -1
node = self.cache[key, "medium"]
self._remove(node) # Pull out of current position
self._insert_at_front(node) # Move to most recently used
return node.value
def put(self, key: int, value: int) -> None:
if key in self.cache:
# Update existing node: remove from list, update value, re-insert
self._remove(self.cache[key])
del self.cache[key, "medium"]
if len(self.cache) >= self.capacity:
# Evict the least recently used node (just before dummy tail)
lru_node = self.tail.prev
self._remove(lru_node)
del self.cache[lru_node.key] # Need the key — that's why Node stores it!
# Create fresh node, insert at front, register in hash map
new_node = Node(key, value)
self._insert_at_front(new_node)
self.cache[key] = new_nodeCritical implementation notes worth calling out in an interview:
- The
Nodestores bothkeyandvalue. When evictingtail.prev, you need the key to delete it from the hash map. If nodes only stored values, you’d have no way to clean up the dictionary. - The
_removeand_insert_at_fronthelpers are not optional. Bothgetandputneed these operations. Factoring them out eliminates duplicated pointer logic. _insert_at_frontrequires four pointer assignments in a specific order. Setnode.prevandnode.nextbefore updating the surrounding nodes’ pointers to avoid overwriting a reference you still need.- Python’s
OrderedDictis a valid shortcut. It’s internally implemented as a hash map + doubly linked list, and itsmove_to_end()method replicates the recency update. Mention it for breadth, but interviewers often ask for the manual implementation.
# Python shortcut using OrderedDict (mention but don't rely on in interviews)
from collections import OrderedDict
class LRUCache:
def __init__(self, capacity: int):
self.capacity = capacity
self.cache = OrderedDict()
def get(self, key: int) -> int:
if key not in self.cache:
return -1
self.cache.move_to_end(key) # Mark as most recently used
return self.cache[key, "medium"]
def put(self, key: int, value: int) -> None:
if key in self.cache:
self.cache.move_to_end(key)
self.cache[key] = value
if len(self.cache) > self.capacity:
self.cache.popitem(last=False) # Evict least recently used (front)Time & Space Complexity
| Operation | Complexity |
|---|---|
get | O(1) |
put | O(1) |
| Space | O(capacity) |
Time: Every operation (hash map lookup, node removal, node insertion) is O(1). The _remove and _insert_at_front helpers each perform a fixed number of pointer assignments regardless of cache size.
Space: The hash map and doubly linked list each hold at most capacity entries (plus two sentinel nodes). Space scales linearly with capacity: O(capacity).
A common follow-up: “How would you make this thread-safe?” Wrap each get and put with a mutex lock. Both operations become atomic critical sections. Under heavy concurrent access, the lock becomes a bottleneck, which leads to discussing sharded caches or lock-free data structures.
Common Interview Mistakes
-
Using a list instead of a doubly linked list for ordering. A Python list’s
remove()is O(n). This is the single most common mistake. Candidates implement a logically correct LRU cache that violates the O(1) requirement. Always justify why a doubly linked list is necessary. -
Forgetting to store the key inside the Node. When evicting
tail.prev, you need its key to delete it from the hash map. Nodes that only store values force a reverse lookup, which is O(n). Storing the key in the node is the clean solution. -
Getting the four pointer assignments in
_insert_at_frontin the wrong order. The new node’sprevandnextmust be set before updatinghead.nextand the old first node’sprev. Updatinghead.nextfirst loses the reference to the node that needs itsprevupdated. -
Not handling the
putupdate case. Whenputis called with an existing key, you must remove the old node before checking capacity and creating a new one. Failing to do so causes a ghost node in the list and a stale reference in the hash map. -
Skipping the sentinel node design. Without dummy head and tail, every insertion and deletion requires
if node.prev is Noneandif node.next is Noneguards. This doubles the code and introduces more places for bugs. -
Reaching for
OrderedDictwithout being able to explain it. Using Python’sOrderedDictis acceptable and elegant, but interviewers frequently follow up with “can you implement this without that built-in?” If you can’t, you’ve shown you know a library shortcut but not the underlying structure. -
Not drawing the data structure before coding. LRU Cache has more moving parts than most problems. Candidates who sketch the linked list layout, head -> [A] <-> [B] <-> [C] -> tail, before writing code catch pointer errors before they happen.
What a Strong Candidate Sounds Like
“The core challenge here is supporting O(1)
getand O(1)putwith eviction. O(1) lookup is straightforward, a hash map. But I also need O(1) recency ordering: when I access or insert a key, it becomes most recently used, and I need to evict the least recently used when at capacity.A list gives me ordering but O(n) removal. A doubly linked list gives me O(1) removal and insertion, if I already have a pointer to the node. So I’ll couple the two: a hash map of key to node, where each node lives in a doubly linked list ordered by recency.
I’ll use sentinel head and tail nodes to eliminate boundary checks. Real nodes always sit between them.
getdoes a map lookup, then removes and reinserts the node at the front.putdoes the same if the key exists, then handles eviction by removingtail.previf at capacity, then inserts a new node at the front.One detail: each node stores its key, not just its value. I need the key to clean up the hash map on eviction. Let me draw the structure and then code it.”
Example Interview Dialogue
Interviewer: Design an LRU cache that supports get and put in O(1) time.
Candidate: Before I design: should get return -1 for a missing key? And does calling put on an existing key count as a recency update?
Interviewer: Yes to both.
Candidate: Got it. O(1) lookup points to a hash map. O(1) recency ordering points to a doubly linked list. Specifically, I need O(1) removal from any position and O(1) insertion at the front. Coupling these two gives me everything: the map stores key-to-node references, the list maintains recency order.
Interviewer: Why doubly linked, not singly linked?
Candidate: Singly linked lists can only remove a node in O(1) if you have a pointer to its predecessor. With only a pointer to the node itself, removal is O(n). In a doubly linked list, each node knows its own prev and next, so I can unlink it in O(1) with just the node reference.
Interviewer: What if two threads call get and put simultaneously?
Candidate: The current implementation isn’t thread-safe. Concurrent modifications to the hash map and linked list could corrupt both structures. To fix this, I’d wrap each get and put with a threading.Lock. Both become atomic critical sections. Under heavy concurrency, the lock becomes a bottleneck. A more scalable design would shard the cache into N independent LRU caches, each with its own lock, reducing contention by a factor of N.
Interviewer: How would you implement an LFU cache instead?
Candidate: LFU evicts the least frequently used key. I’d need a frequency map (key -> count) and a grouping structure (count -> doubly linked list of keys at that frequency). I’d also track the current minimum frequency. On get or put, I’d increment the key’s frequency, move it from its old frequency bucket to the new one, and update the minimum if the old bucket becomes empty. Same O(1) complexity, meaningfully more complex bookkeeping.
Related Problems
LRU Cache sits at the intersection of system design and data structures. These problems build on the same hash map + ordered structure pattern:
- LFU Cache (LeetCode #460). Evict by frequency instead of recency. Requires frequency buckets on top of the LRU structure.
- All O(1) Data Structure (LeetCode #432). Insert, delete, and get min/max in O(1). Same hash map + doubly linked list design philosophy.
- Design Browser History (LeetCode #1472). Simpler ordered history structure. Good warm-up for pointer manipulation.
- Design HashMap (LeetCode #706). Build a hash map from scratch. Foundational for understanding the lookup layer in LRU.
The jump from LRU Cache to LFU Cache (#460) is the single most common follow-up in senior engineering interviews. If you can explain the frequency-bucket extension clearly, you demonstrate that you understand the LRU design deeply enough to generalize it.
Practice This in a Mock Interview
This walkthrough gives you the architectural reasoning, the pointer logic, and the design vocabulary to answer every interviewer question. But LRU Cache has one of the widest gaps between “I understand this” and “I can implement it cleanly under pressure” of any problem in the interview canon.
The _insert_at_front pointer assignments, the eviction key lookup, the sentinel node setup: each is individually simple. Combined, under a ticking clock, with an interviewer probing your design choices mid-implementation, they create exactly the conditions where candidates who’ve only read the solution stall out. The only way to close that gap is to build it from scratch, out loud, with follow-up questions, until the pointer operations feel as natural as writing a for loop.
Start a mock interview for LRU Cache on Intervu.
Related Problems to Practice
- Implement Trie — Building a data structure from scratch.
- Min Stack — Stack design with auxiliary tracking.
- Find Median from Data Stream — Streaming data structure design.
Further reading:
- How to Prepare for a Coding Interview in 2026, the complete roadmap and study plans
- Why LeetCode alone isn’t enough, and what to practice instead
- Practice any LeetCode problem as a live mock interview
- The Grind 75 Pathway, a structured study plan with AI practice links
- Browse all walkthroughs on GitHub, condensed solutions with code