Implement Trie (Prefix Tree) — Coding Interview Walkthrough

You’re in a coding interview. The interviewer says: “Implement a Trie that supports insert, search, and startsWith.” You know it’s a tree where each edge is a character. You’ve seen the solution before. But now you need to explain your node design out loud, justify using a hash map over a fixed array, distinguish search from startsWith without mixing them up, and handle the “what about delete?” follow-up while someone watches. That’s a very different challenge.
This walkthrough covers how that conversation unfolds: the clarifying questions that signal design maturity, the exact node structure interviewers want to see, and the is_end flag mistake that catches even prepared candidates.
The Problem
Implement a data structure called a Trie (pronounced “try”) that supports three operations:
insert(word): Insert a word into the trie.search(word): ReturnTrueif the word exists in the trie,Falseotherwise.startsWith(prefix): ReturnTrueif any previously inserted word starts with the given prefix.
Example
Input
["Trie", "insert", "search", "search", "startsWith", "insert", "search"]
[[], ["apple"], ["apple"], ["app"], ["app"], ["app"], ["app"]]Output
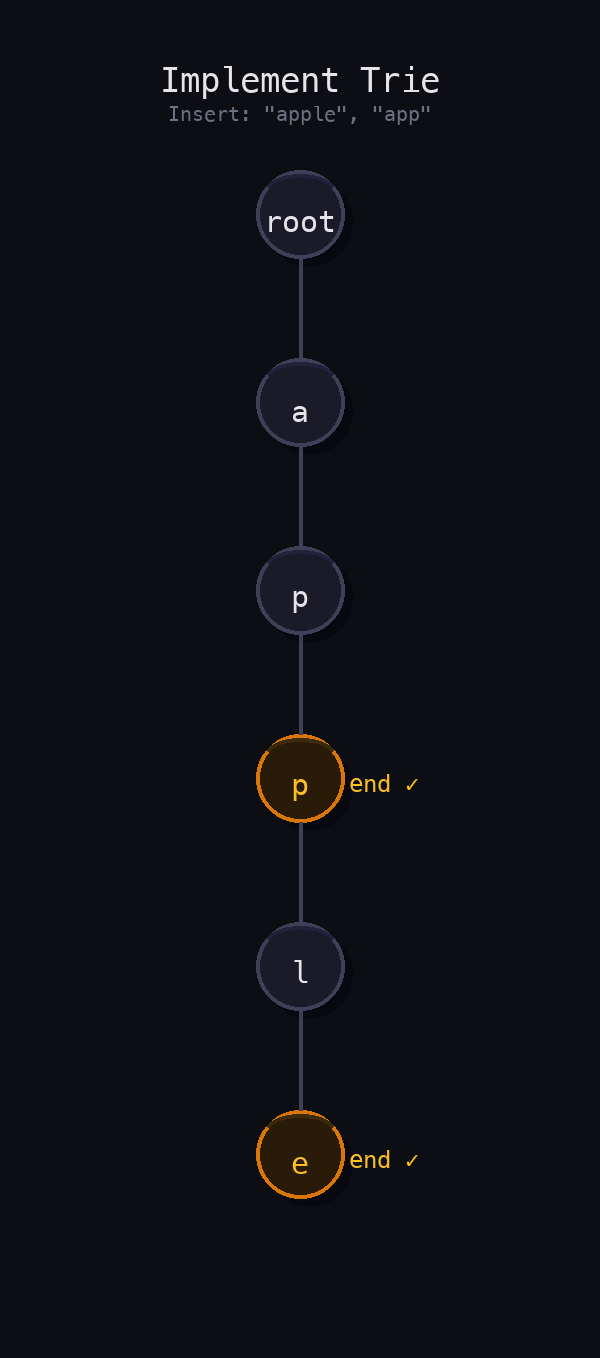
[null, null, true, false, true, null, true]After inserting "apple", searching for "apple" returns true and searching for "app" returns false, because "app" was never fully inserted. However, startsWith("app") returns true because "apple" begins with "app". After inserting "app" directly, searching for it also returns true. This illustrates the crucial distinction between a complete word and a prefix path in the trie.
Already comfortable with the solution? Practice it in a mock interview →
What Interviewers Are Actually Testing
This problem is really about your ability to design a recursive node-based data structure and reason through its operations methodically.
| Skill | What Interviewers Observe |
|---|---|
| Data structure design | Can you model a Trie node with children and an end-of-word flag? |
| Pointer/reference thinking | Do you traverse nodes correctly without losing references? |
| Edge case awareness | Do you handle empty strings, overlapping words, and prefixes-as-words? |
| Clean OOP design | Is your class well-structured with clear responsibilities? |
| Verbal communication | Can you explain the structure before touching the keyboard? |
Step 1: Clarifying Questions
Before writing a single line of code, ask these questions. They signal maturity and help you avoid wrong assumptions.
1. What characters can words contain? It matters. If it’s only lowercase English letters, you can use a fixed-size array of 26 children. If it’s unicode or mixed case, you’ll need a hash map. Clarify upfront.
2. Can search and startsWith be called on words that were never inserted?
Yes, that’s the whole point. But confirming this ensures you’re not building something that assumes all queries are valid.
3. Are there any constraints on word length or the total number of insertions? Knowing this helps you reason about space usage. A trie with millions of long words has different memory characteristics than one with a few short ones.
4. Should search be case-sensitive?
If the problem says lowercase only, great. But asking shows you think about real-world use cases.
5. Is there a delete operation we need to support later?
Not in this problem, but asking this shows you’re thinking about extensibility, a quality senior engineers look for.
Step 2: A First (Non-Optimal) Idea
The brute-force approach is to just use a Python set to store all inserted words.
class Trie:
def __init__(self):
self.words = set()
def insert(self, word):
self.words.add(word)
def search(self, word):
return word in self.words
def startsWith(self, prefix):
return any(w.startswith(prefix) for w in self.words)| Approach | Time (insert/search) | Time (startsWith) | Space |
|---|---|---|---|
| Set-based | O(1) avg / O(m) | O(n × m) | O(n × m) |
This works correctly, but it’s not what the interviewer is looking for, and startsWith is the giveaway. It scans every stored word one by one, making it O(n × m) where n is the number of words and m is the prefix length. For large dictionaries, this is far too slow.
More importantly, this approach completely sidesteps the intent of the problem: building a tree-based data structure. If you propose this in an interview without quickly pivoting to the real solution, you’ll likely not move forward.
Step 3: The Key Insight
Words that share a prefix should share nodes in memory. Instead of storing three separate strings, a trie stores shared character paths. Insert walks and creates nodes character by character. Search walks and checks the end-of-word flag. StartsWith walks and returns
Trueif the path exists at all.
Think about the words "cat", "car", and "card". They all start with "ca". Instead of storing three separate strings, a trie stores:
root → c → a → t (end)
r (end) → d (end)The "ca" path is shared. This means:
- Insert just walks (and creates) nodes character by character.
- Search walks existing nodes and checks if the final node is marked as a word end.
- StartsWith walks existing nodes and returns
Trueif the path exists at all, no need to check the end-of-word flag.
The critical realization is that search and startsWith are almost identical. The only difference is whether you check is_end at the final node. Once you see that, the implementation becomes clean and elegant.
Each node needs just two things:
- A dictionary (or array) of children, keyed by character.
- A boolean flag marking whether this node completes a valid word.
Step 4: Optimal Strategy
- Define a
TrieNodeclass with achildrendict and anis_endboolean. - The
Trieclass holds arootnode (an emptyTrieNode). - Insert: Start at root, iterate over each character. If a child node for that character doesn’t exist, create one. Move to the child. After all characters, mark
is_end = True. - Search: Start at root, iterate over each character. If a child for that character doesn’t exist, return
False. After all characters, returnnode.is_end. - StartsWith: Same as search, but return
Trueat the end regardless ofis_end. You only care that the path exists.
Python Implementation
class TrieNode:
def __init__(self):
# Maps each character to its child TrieNode
self.children = {}
# True if this node marks the end of a complete word
self.is_end = False
class Trie:
def __init__(self):
self.root = TrieNode()
def insert(self, word: str) -> None:
node = self.root
for char in word:
# Create a new node if this character path doesn't exist yet
if char not in node.children:
node.children[char] = TrieNode()
node = node.children[char]
# Mark the final node as a complete word
node.is_end = True
def search(self, word: str) -> bool:
node = self.root
for char in word:
if char not in node.children:
return False # Path breaks — word doesn't exist
node = node.children[char]
# Must reach end AND the node must be a complete word
return node.is_end
def startsWith(self, prefix: str) -> bool:
node = self.root
for char in prefix:
if char not in node.children:
return False # No word with this prefix exists
node = node.children[char]
# If we traversed the full prefix without breaking, it exists
return TrueNotice how search and startsWith share an almost identical traversal loop. The only difference is the final return value. This is a clean signal that the design is right.
Time & Space Complexity
| Operation | Time Complexity | Space Complexity |
|---|---|---|
insert(word) | O(m), m = word length | O(m), new nodes per character |
search(word) | O(m) | O(1), no new allocations |
startsWith(prefix) | O(m) | O(1) |
| Total space | O(n × m), n words, avg length m |
Time: Each operation traverses the word character by character, doing O(1) hash map lookups at each step. Total: O(m) per operation.
Space: The trie’s real power shines when many words share prefixes. In the worst case (no shared prefixes), you use O(n × m) space, but in practice, tries compress shared prefixes significantly compared to storing full strings separately.
This is a common interview follow-up: “Can you reduce space further?” For lowercase letters only, you could use a fixed-size array of 26 instead of a hash map, O(1) space per node relative to character set size, though the total space remains O(n × m) in the worst case.
Common Interview Mistakes
-
Forgetting the
is_endflag. A lot of candidates build the traversal correctly but forget to mark, or check, the end-of-word flag. This causessearch("app")to returntrueeven if only"apple"was inserted. -
Mixing up
searchandstartsWith. Both methods look nearly identical. Candidates sometimes returnTruefromsearchwithout checkingis_end, effectively making it behave likestartsWith. Slow down and be explicit. -
Creating a new root per method call. This is a subtle bug: if you initialize
node = TrieNode()instead ofnode = self.rootat the top of your methods, you’re starting from an empty node, not the actual trie. -
Not handling the empty string. What should
insert("")do? What aboutsearch("")? The loop handles these gracefully (zero iterations), but candidates who haven’t thought about edge cases may be caught off-guard if the interviewer asks. -
Using a fixed array of 26 instead of a dict without justification. Using
[None] * 26is a valid optimization for lowercase letters, but jumping straight to it without explaining why (and without asking about character constraints first) suggests you memorized the solution rather than reasoned through it. -
Coding before explaining. Tries are one of those problems where a 60-second verbal explanation of the node structure dramatically reduces bugs during implementation. Candidates who dive straight into code often lose track of when to create nodes vs. traverse them.
-
Confusing
startsWithwith exact match. Reading the problem too quickly and implementingstartsWithas an exact search is a common mistake. The method name is a clue: it checks a path, not a complete word.
What a Strong Candidate Sounds Like
“I’m thinking about this as a tree where every edge represents a character. Each node has a dictionary of children, one entry per distinct character, and a boolean flag to mark whether we’ve reached the end of a valid word. Insert just walks the tree and creates nodes as needed. Search does the same traversal but checks the
is_endflag at the last node. StartsWith is identical to search except we don’t care aboutis_end, we just want to know the path exists. One thing I want to confirm: are we only dealing with lowercase letters? Because that affects whether I use a fixed array or a hash map for children.”
This kind of response shows design thinking, attention to tradeoffs, and the habit of clarifying constraints.
Example Interview Dialogue
Interviewer: How would you implement the startsWith method?
Candidate: It’s almost the same as search. I’d traverse the trie character by character using the prefix. If at any point the next character doesn’t exist as a child, I return False. If I make it through all the characters, I return True, regardless of whether the last node has is_end set.
Interviewer: What if someone inserts "app" and then calls startsWith("apple")? Would that return True?
Candidate: No, and that’s a great edge case. startsWith("apple") would fail when it tries to follow the "l" edge from the node at "app", because that path was never created. So it correctly returns False.
Interviewer: Nice. What’s the space complexity of inserting n words of average length m?
Candidate: Worst case is O(n × m). That’s when no words share any prefixes and we create a fresh node for every character. But in practice, shared prefixes mean the actual space usage is often much lower than that bound.
Related Problems to Practice
Implement Trie is the entry point for the trie family. These problems all build on the same node-based traversal and prefix-matching logic:
- Design Add and Search Words Data Structure (LeetCode #211). Adds wildcard
.matching to trie search, a great next step. - Word Search II (LeetCode #212). Uses a trie to efficiently prune a backtracking grid search.
- Replace Words (LeetCode #648). Uses a trie to find the shortest root prefix in a sentence.
- Longest Word in Dictionary (LeetCode #720). Builds a trie and checks which words are formed step by step.
- Search Suggestions System (LeetCode #1268). Classic trie autocomplete, directly mirrors real-world use.
The jump from #208 to #212 is one of the most common interview escalations. Both use trie traversal, but Word Search II combines it with backtracking on a 2D grid, testing whether you can adapt the data structure to a new search context.
From the Intervu walkthrough collection:
- Word Search — DFS backtracking on grids with character matching.
- Word Break — Dictionary-based DP with prefix lookups.
- LRU Cache — Designing a data structure from scratch.
Practice This in a Mock Interview
Reading through this explanation makes tries feel intuitive. The node structure is clean, the operations are short, and the distinction between search and startsWith is obvious once stated. But this problem has a consistent failure mode in interviews: candidates who know the structure still forget the is_end flag, initialize node = TrieNode() instead of node = self.root, or stumble when the interviewer asks how startsWith("apple") behaves after inserting only "app".
The gap between understanding and performing is real. The only way to make the design explanation, the traversal logic, and the edge cases feel automatic is deliberate practice under realistic conditions: a timer, an interviewer asking questions, and immediate feedback on where you hesitated.
Start a mock interview for Implement Trie on Intervu.
Further reading:
- How to Prepare for a Coding Interview in 2026, the complete roadmap and study plans
- Why LeetCode alone isn’t enough, and what to practice instead
- Practice any LeetCode problem as a live mock interview
- The Grind 75 Pathway, a structured study plan with AI practice links
- Browse all walkthroughs on GitHub, condensed solutions with code