Clone Graph — Coding Interview Walkthrough
You’re in a coding interview. The interviewer says: “Clone this undirected graph.” You know it’s DFS or BFS. But the catch — the one that breaks most candidates — is cycles. Without tracking which nodes you’ve already cloned, your traversal loops forever. Clone Graph is less about the graph traversal itself and more about using a hash map to break cycles and map original nodes to their clones.
The Problem
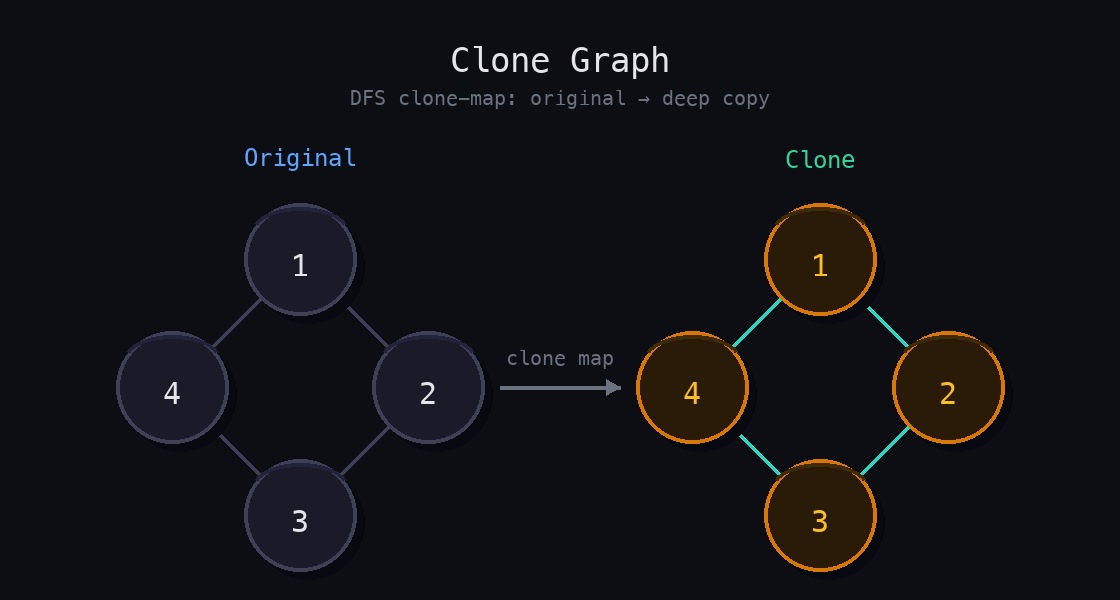
Given a reference to a node in a connected undirected graph, return a deep copy (clone) of the graph. Each node contains a val (integer) and a neighbors list (list of adjacent nodes).
Example
Input: adjList = [[2,4],[1,3],[2,4],[1,3]]
Output: A deep copy of the graph with the same adjacency structure.
Already comfortable with the solution? Practice it in a mock interview →
What Interviewers Are Actually Testing
| Skill | What Interviewers Observe |
|---|---|
| Cycle detection | Do you use a visited/cloned map to prevent infinite loops? |
| Deep vs. shallow copy | Do you create new node objects with new neighbor lists? |
| DFS vs. BFS | Can you implement both? |
| Hash map as clone registry | Do you map original nodes to their clones before recursing? |
| Null/empty graph | Do you handle node = None at the start? |
Step 1: Clarifying Questions
- Can the graph have cycles? Yes — it’s undirected, so every edge creates a cycle (A→B and B→A). This is why you need a visited map.
- Is the graph always connected? Yes — a single DFS from the given node reaches all nodes.
- Can
nodebeNone? Yes — returnNonein that case.
Step 2: The Key Insight
The clone map does two jobs at once: it records visited nodes (preventing infinite loops on cycles) and maps original nodes to their clones (letting neighbors be wired up correctly). Before recursing into a node’s neighbors, create the clone and register it in the map. That way, when a cycle brings you back to an already-cloned node, you return the cached clone instead of creating a duplicate.
Step 3: Algorithm (DFS)
- If
nodeisNone, returnNone. - Maintain a
cloned = {}dict mapping original node references to their clones. - Define
dfs(node):- If
nodeis incloned, returncloned[node]. - Create
clone = Node(node.val)and register it:cloned[node] = clone. - For each neighbor, recurse:
clone.neighbors.append(dfs(neighbor)). - Return
clone.
- If
Python Implementation
DFS (recursive):
def cloneGraph(node: Node) -> Node:
if not node:
return None
cloned = {}
def dfs(original: Node) -> Node:
if original in cloned:
return cloned[original]
clone = Node(original.val)
cloned[original] = clone # Register BEFORE recursing
for neighbor in original.neighbors:
clone.neighbors.append(dfs(neighbor))
return clone
return dfs(node)BFS (iterative):
from collections import deque
def cloneGraph_bfs(node: Node) -> Node:
if not node:
return None
cloned = {node: Node(node.val)}
queue = deque([node])
while queue:
current = queue.popleft()
for neighbor in current.neighbors:
if neighbor not in cloned:
cloned[neighbor] = Node(neighbor.val)
queue.append(neighbor)
cloned[current].neighbors.append(cloned[neighbor])
return cloned[node]Time & Space Complexity
| Aspect | Complexity |
|---|---|
| Time | O(V + E) — each node and edge visited once |
| Space | O(V) — clone map holds one entry per node |
Common Interview Mistakes
-
Registering the clone after recursion. If you add the clone to
clonedonly after processing neighbors, any cycle recurses infinitely. Register immediately after creation. -
Shallow copying neighbors. Appending the original neighbor objects gives you a shallow copy. You must append the cloned neighbor.
-
Not handling
None. ReturnNonebefore accessing any properties. -
Using
node.valas key instead of the node object. Works here because values are unique, but it’s fragile for variants.
What a Strong Candidate Sounds Like
“I’ll use DFS with a hash map that both tracks visited nodes and maps originals to their clones. The key is to register each new clone before recursing into its neighbors — that way, when a cycle brings DFS back to an already-visited node, I return the cached clone instead of looping forever. Time is O(V + E).”
Example Interview Dialogue
Interviewer: Why do you add to the clone map before recursing?
Candidate: Because the graph has cycles. If node A points to B and B points back to A, DFS for A recurses into B, which tries to recurse into A again. If A isn’t in the clone map yet, we’d recurse infinitely. By registering A’s clone first, any subsequent visit just returns the cached clone.
Interviewer: Can you do it iteratively?
Candidate: Yes — BFS with a queue. I seed with the starting node, then for each dequeued node I iterate neighbors, create clones for unseen ones, wire up the cloned neighbors, and enqueue unvisited ones. The clone map plays the same role.
Related Problems to Practice
- Number of Islands — DFS/BFS graph traversal with visited tracking.
- Course Schedule — Graph cycle detection using DFS.
- Flood Fill — Grid DFS with implicit visited.
- Accounts Merge — Graph grouping with Union Find.
Practice This in a Mock Interview
Clone Graph is the rare problem where the implementation is short but the explanation is what separates candidates. Being able to articulate why you register the clone before recursing — and what happens if you don’t — is the core of a great answer.
Start a mock interview for Clone Graph on Intervu.
Further reading:
- How to Prepare for a Coding Interview in 2026, the complete roadmap
- Why LeetCode alone isn’t enough, and what to practice instead
- Practice any LeetCode problem as a live mock interview
- The Grind 75 Pathway, a structured study plan with AI practice links
- Browse all walkthroughs on GitHub