FAANG Coding Interview Guide 2026: Google, Meta, Amazon, Netflix & Apple Compared
Most FAANG coding guides treat the five companies as interchangeable: study LeetCode, learn patterns, done. That advice costs candidates offers. Google, Meta, Amazon, Netflix, and Apple run structurally different coding rounds that demand different preparation strategies, different time-management instincts, and different in-interview behaviors. This guide leads with the companies. We compare them head-to-head first, go deep into each one, then close with the universal toolkit.
Key Takeaways:
- Google rewards deliberate reasoning and follow-up depth; Meta rewards speed (2 problems in 35 min)
- Amazon’s OA includes a debugging round almost nobody prepares for
- Netflix asks the hardest applied problems but weights coding lowest in the loop
- Apple explicitly grades code quality: naming, modularity, error handling
- The 5-phase protocol (clarify, example, approach, code, test) works at all five companies with company-specific timing adjustments
Master Comparison: All Five Companies Side by Side

Read this before anything else. Every preparation decision, which problems to drill, how to manage in-interview time, which signals to optimize, should be anchored to the specific company you’re targeting.
| Dimension | Meta | Amazon | Netflix | Apple | |
|---|---|---|---|---|---|
| Coding rounds | 2-3 onsite + phone screen | 2 onsite + phone screen | 1-2 onsite + OA | 1-2 onsite + phone screen | 2-3 onsite + phone screen |
| Problems / round | 1-2 + follow-up escalation | 2 (hard constraint) | 1 per round | 1-2 applied | 1 domain-specific |
| Round duration | 45 min | 35 min | 60 min (coding: ~40 min) | 45-60 min | 45-60 min |
| Platform | Google Docs (no IDE) | CoderPad (no execute) | CodeSignal OA / CoderPad onsite | CoderPad | Varies by team |
| Code execution | None (manual trace) | None (manual trace) | OA: yes / Onsite: no | None (manual trace) | Sometimes |
| Difficulty | Medium to Medium-Hard (follow-ups escalate) | Medium-Hard | Medium-Hard | Hard (applied) | Medium (domain-deep) |
| Problem style | Abstract DSA + follow-ups | Abstract DSA, two at a time | Applied framing + debugging OA | Real-world systems applied | Domain-specific craft |
| Top problem topics | Graphs, trees, DP | Arrays, strings, trees, graphs | Trees, graphs, arrays, DP | Concurrency, intervals, systems | Team-determined |
| Question recycling | Moderate | High (LC tag drillable) | Moderate | Low (team-custom) | Low (team-custom) |
| Follow-up escalation | Core mechanic (expected) | Rare (no time) | Occasional | Applied extension | Domain follow-ups |
| Communication weight | Very High (GCA signal) | Medium | Medium | High | Medium |
| Code quality signal | High | Medium | Medium | Medium | Very High (explicitly graded) |
| Standardization | High | Very High (same for all) | High | Low (team-varies widely) | Low (team-varies widely) |
| Company-specific prep | Top 50 Google-tagged LC | LC Meta 3-month tag | Debugging drills + OA simulation | Netflix tech blog + domain | Team domain deep study |
| #1 failure mode | Silent when escalation hits | Overrunning problem one | Running over into LP time | Under-researching the team | Ignoring code quality |
How to use this table: Identify your target company first. Read its column top to bottom; this tells you exactly where to allocate prep time differently from generic advice. Interviewing Google and Meta in the same week? You need two completely different time-management instincts: deliberate-and-escalate for Google, sprint-and-pivot for Meta. The companies are not interchangeable.
What’s Changed in 2026, and What Hasn’t
“Coding rounds still exist, but they often focus on reading existing code, debugging a broken path, or extending a partial solution, rather than solving a fresh puzzle from scratch.” Interviewing.io, January 2026
The shift is real but nuanced. LeetCode-style problems remain the backbone of Google and Meta rounds. What has changed is what they are measuring, and that shift looks different at each company.
Speed is no longer the primary signal. AI tools write competent boilerplate. Interviewers now probe reasoning, trade-off articulation, and edge-case discipline: signals that can’t be autocompleted. A candidate who solves a hard problem silently rates lower than one who solves a medium problem with crystal-clear narration.
Always state the brute force before optimizing. This is established best practice across all FAANG companies: name the naive solution and its complexity, identify the bottleneck, then derive the optimization explicitly. Jumping straight to an optimal solution without that reasoning step, even if the solution is correct, makes it harder for the interviewer to assess how you think.
Debugging and code reading are spreading. Amazon’s OA has included a debugging round for years. The pattern is extending: finding the logical bug in a working-but-wrong snippet tests a different muscle than writing from scratch.
What hasn’t changed: you still need strong DSA fundamentals, pattern recognition, and the ability to implement solutions cleanly under time pressure. The foundation is unchanged. The evaluation layer on top has grown more sophisticated.
Google: Depth, Escalation & GCA
| Coding rounds | 2-3 onsite (45 min each) |
| Phone screen | 1-2 problems, 45 min |
| Problems / round | 1-2 + follow-up escalation |
| Platform | Google Docs (no IDE, no execution) |
| Difficulty | Medium to Medium-Hard; follow-ups escalate depth |
| After loop | Hiring Committee reviews holistically |
What Google’s Coding Round Actually Measures
Google evaluates General Cognitive Ability (GCA) through coding, not rote pattern recall. They want to see you form a mental model and reason your way to a solution, then adapt when the problem changes. The base problem is typically medium difficulty. Follow-up escalation is a core mechanic, not an exception; it’s how the round gets harder, pushing the problem into territory you couldn’t have memorized, to watch you reason under pressure.
Every hint an interviewer provides is a recorded signal. Missing a return statement that the interviewer points out is a rating deduction. Needing prompting on complexity is a deduction. Self-correction is a positive; interviewer-prompted correction is a negative.
The Follow-Up Escalation Mechanic
# Typical Google in-round escalation:
Round opens: "Find the k-th largest element in an array."
# Expected: quickselect O(n) avg, or min-heap O(n log k).
# State brute force (sort: O(n log n)) first.
Escalation 1: "Now the input is a data stream — elements arrive one at a time."
# Can't re-sort each time. Expected: min-heap of size k.
# O(log k) per insert, O(1) peek at k-th largest.
Escalation 2: "What if k itself changes dynamically?"
# Heap doesn't support arbitrary-k changes efficiently.
# Expected: BST / order-statistic tree; discuss trade-offs.
Escalation 3: "How would you handle this at 10M queries/second?"
# Now it's a systems problem: partitioned heaps,
# distributed aggregation, approximate top-k (Count-Min Sketch).
# This is where senior candidates separate themselves.
# The escalation reveals whether you understand WHY
# your solution works — not just that it works.Google’s Problem Profile
- Graphs & BFS/DFS: Most common. Adjacency list representations, cycle detection, shortest paths, connected components. See our word ladder walkthrough and number of islands walkthrough.
- Trees: Binary trees, BSTs, N-ary trees: traversal, construction, path problems. See our binary tree level order walkthrough.
- Dynamic Programming: 1D and 2D DP; interviewers probe the recurrence and base cases, not just the final answer. See our coin change walkthrough.
- Arrays & Strings: Often as warmup or follow-up base: two pointers, prefix sums, sliding window.
- Complexity analysis is requested mid-solution, not just at the end.
Google-Specific Preparation
- Code in Google Docs. Open a blank Doc with no extensions. Write actual code in it. The disorientation of no color feedback and no autocomplete needs to be trained away before the actual interview.
- Use the top 50 Google-tagged LC problems (medium difficulty focus). Google recycles themes: graphs, intervals, and trees dominate the tag. The phone screen is typically medium; onsite problems are medium to medium-hard, with difficulty increasing through follow-ups rather than the opening problem itself being hard-rated.
- Practice generating follow-ups yourself. After every practice problem, ask: what if n is 10x larger? What if the input is a stream? What if elements can be updated? Answer them out loud, immediately.
- Narrate complexity mid-code. Google interviewers may interrupt to ask “what’s the complexity of what you have so far?” Build the habit of noting complexity as you write each major operation, not just at the end.
Google’s #1 Coding Killer: Going silent when the follow-up escalation hits. The escalation is intentional; most candidates slow down. Your job is to keep reasoning out loud: “The heap approach breaks when k changes because we’d need to resize in O(k) time. Let me think about whether a balanced BST changes that…” Structured uncertainty spoken aloud is always scored higher than silent certainty that never arrives.
Practice follow-up escalation with an AI interviewer that pushes back: Try a Google-style mock interview →
Meta: Speed, Precision & Recycled Questions
| Coding rounds | 2 onsite (35 min each) |
| Phone screen | 1 problem, 45 min |
| Problems / round | 2 (hard constraint) |
| Platform | CoderPad (no execution) |
| Difficulty | Medium-Hard (harder end) |
| Question pool | High recycling (tag-drillable) |
What Meta’s Coding Round Actually Measures
Meta’s round is a test of speed under precision constraints. Two problems in 35 minutes, roughly 17 minutes per problem including clarification, approach, code, and trace, leaves almost no room for deliberation. Meta interviewers are available but the pace leaves little room for back-and-forth. Plan to self-solve.
Meta’s process is the most standardized of any FAANG company. The flip side: Meta recycles questions more than any other company. Drilling the LeetCode Meta company tag (3-month filter, Premium required) is the single highest-ROI preparation investment for Meta specifically.
The Meta Time Budget
# Meta: 35 minutes, 2 problems. Strict internal budget:
Problem 1 (target: 15 min)
Clarify: 1-2 min (short — don't over-ask)
Approach: 2-3 min (brute force → optimize fast)
Code: 8-9 min
Trace: 1-2 min
Problem 2 (target: 15 min) [5 min buffer remains]
Same structure.
# HARD RULE: If problem 1 hits 18 min with no complete solution,
# submit the brute force, state its complexity, pivot to problem 2.
# Partial credit on two problems beats a perfect solution on one.
# Every time.
# DRILL: Set a 17-min timer. Solve a medium LC problem.
# When it expires, immediately start another.
# Do this 3x/week until the context-switch is automatic.Meta’s Problem Profile
- Arrays & Strings: Dominant. Sliding window, two pointers, prefix sums appear in most loops.
- Trees: Binary tree traversal, LCA, path problems: consistent presence.
- Graphs: BFS/DFS, connected components at the harder problem slot.
- Code is not executed. Know your language APIs cold; API hesitation costs 1-2 minutes you don’t have.
Meta-Specific Preparation
- Drill the Meta tag on LeetCode. 3-month filter on LeetCode Premium. Meta recycles questions more than any other FAANG; this is directly exploitable.
- Practice two problems back-to-back on a 35-minute timer. The context-switch under time pressure is a different cognitive muscle. Train it explicitly.
- Know your language’s standard library cold. No time to think about API details.
collections.Counter,defaultdict,heapq,deque: fluency is non-negotiable.
Meta’s #1 Coding Killer: Overrunning problem one. Candidates who spend 25 minutes solving problem one perfectly and have 10 minutes left for problem two almost never pass. The format rewards time management as a skill equal to algorithmic ability. Build a hard internal clock. When you hit 15 minutes on problem one with no complete solution, pivot consciously and deliberately.
Train the 2-problem sprint under time pressure: Practice on a 35-minute timer with Intervu →
Amazon: Applied Problems & the Debugging OA
| OA (pre-loop) | 2 coding + debugging + LP MCQs |
| Onsite coding | 1-2 rounds, 60 min each |
| Problems / round | 1 coding + LP discussion |
| OA platform | CodeSignal (code executes) |
| Onsite platform | CoderPad (no execution) |
| Unique mechanic | Debugging round in OA |
What Amazon’s Coding Round Actually Measures
Amazon’s coding round has one structural constraint that sets it apart: every onsite coding round also contains Leadership Principle questions in the same 60 minutes, leaving only ~40 minutes for coding. This is not a hidden trap; it’s by design. Amazon explicitly evaluates how you perform under a tighter coding window while being expected to shift into behavioral mode.
Amazon’s OA is the most distinctive pre-loop assessment in FAANG. Beyond two standard coding problems, it includes a debugging round: five code snippets each containing one logical bug to find and fix in ~20 minutes. This tests code-reading ability, a skill most candidates skip preparing for entirely.
The Debugging Round in Detail
# 5 snippets, ~20 min, one logical bug each.
# Bugs are always logic errors — code runs but produces wrong output.
# Bug type 1: Off-by-one in loop bound
for i in range(0, n): # BUG: should be range(0, n-1)
swap(arr, i, i+1) # triggers index out-of-bounds
# Bug type 2: Flipped comparison operator
if left < right: # BUG: should be left > right
result = left # picks wrong side of min/max
# Bug type 3: Missing return in recursive branch
def search(node, target):
if node is None: return False
if node.val == target: return True
search(node.left, target) # BUG: missing return
return search(node.right, target)
# Bug type 4: Wrong base case in DP
dp[0] = 1; dp[1] = 1 # BUG: dp[1] should be 2 (climbing stairs)
# Bug type 5: Incorrect termination in binary search
while lo < hi: # BUG: should be lo <= hi
... # misses the exact midpoint case
# Strategy: read each snippet in full before assuming
# where the bug is. Trace with a 2-3 element example.
# Common patterns: flipped comparisons, off-by-ones,
# missing returns, wrong base cases.Amazon’s Problem Profile
- Trees & Graphs: Most common. N-ary trees, BFS/DFS applications, path problems.
- Problems often have a practical framing: warehouse routing, recommendation queues, order processing. Map these to the underlying DSA pattern.
- OA runs code. Syntax errors surface. Verify your solution compiles cleanly before submitting.
- Bar Raiser round may include additional coding. Treat every round as potentially having a coding component.
Amazon-Specific Preparation
- Practice the debugging round explicitly. Take any solved LC problem, introduce a subtle logical bug, and practice locating it in under 3 minutes. Almost nobody prepares for this; it’s one of the highest-leverage preparation gaps for Amazon.
- Budget onsite coding time at 40 minutes, not 60. At the 35-minute mark, wrap up your coding explanation and pivot to LP regardless of where you are. Going over burns the LP signal, which can disqualify a strong technical candidate.
- Practice with CodeSignal for the OA. It runs your code. Know your language well enough that it compiles on first submission.
Amazon Coding Trap: Running the full 60 minutes on coding and leaving no time for the LP discussion. Amazon interviewers score both components. A technically perfect coding answer with zero LP signal is a near-certain rejection. Hard-cap your coding window at 35-40 minutes and pivot deliberately, regardless of how close you are to finishing.
Netflix: Hard, Applied & Team-Specific
| Phone screen | 1 problem + culture intro |
| Onsite coding | 1-2 rounds, 45-60 min |
| Problem style | Real-world applied, not abstract |
| Platform | CoderPad (no execution) |
| Difficulty | Hard (practically applied) |
| Standardization | Low (varies by team) |
What Netflix’s Coding Round Actually Measures
Netflix’s coding rounds are the most practically applied of any FAANG company. Rather than abstract DSA puzzles, Netflix leans toward problems that map directly to their engineering domain: in-memory file systems, concurrent read/write structures, streaming interval scheduling, CDN cache eviction. Some teams extend the coding problem: solve the algorithm, then explain how you’d deploy it in production.
Paradoxically, coding carries the lowest weight in Netflix’s overall loop. System design and culture fit are the primary filters. This doesn’t mean underprepare coding. The problems they ask are harder and more applied than the median FAANG company. It means that if your coding is solid, the bigger risk is the applied reasoning and domain-specific thinking around it.
Netflix’s Problem Profile
- Applied data structures: In-memory file systems (HashMap + Trie), LRU/LFU caches, interval merging.
- Concurrency: More than any other FAANG company. Threading, read/write locks, race condition identification.
- Graphs & trees with a systems context (routing, topology, service dependencies).
- Team-variance is significant: streaming infra asks different problems than the payments or content delivery team.
Netflix-Style Problem Example
# Real candidate report (2025):
# "Design an in-memory file system with mkdir, ls, addContentToFile.
# Interviewer then pushed: 'Now handle concurrent reads and writes.'"
# Phase 1 — Data model:
class FileSystem:
def __init__(self):
self.dirs = {} # path → set of children
self.files = {} # path → content
# Phase 2 — Concurrency extension (what Netflix actually probes):
import threading
class FileSystem:
def __init__(self):
self.dirs = {}
self.files = {}
self._rlock = threading.Lock() # readers-writer pattern
def ls(self, path): # shared read — multiple OK
with self._rlock: ...
def addContentToFile(self, path, content): # exclusive write
with self._rlock: ...
# Netflix follow-up: "What happens if two writers race on the same path?"
# They want to see you reason about invariants, atomicity, and
# failure modes — not just use a lock.Netflix-Specific Preparation
- Read the Netflix Tech Blog before your interview. Understanding their CDN (Open Connect), microservices patterns, and resilience engineering (Chaos Monkey) turns abstract problems into familiar territory.
- Ask your recruiter about the team’s tech stack. Netflix discloses this early. If the team owns a Java-based video pipeline, practice concurrency in Java and know how adaptive bitrate streaming works conceptually.
- Practice the “algorithm + deployment” extension. After solving any problem, ask: how do I make this thread-safe? What breaks at 10M concurrent users? What’s the failure mode?
Netflix Coding Tip: Netflix’s process is not standardized. The team you interview with shapes the entire experience. Use your recruiter conversation to extract team context, then tailor your domain preparation in the final 1-2 weeks. A candidate who researches the specific team’s architecture consistently outperforms one who prepares generically.
Apple: Craft, Domain Depth & Code Quality
| Phone screen | 1-2 rounds, coding + domain |
| Onsite coding | 2-3 of 4-6 total rounds |
| Problems / round | 1 domain-specific |
| Difficulty | Medium (but domain-deep) |
| Unique signal | Code quality explicitly graded |
| Standardization | Low (heavily team-dependent) |
What Apple’s Coding Round Actually Measures
Apple is the most team-dependent interview of any FAANG company. CoreML (Swift performance, on-device inference, memory management) looks nothing like Maps (spatial graph algorithms, routing) or App Store infrastructure (distributed systems, consistency). The through-line is craftsmanship: Apple engineers take pride in the quality of their code, and interviewers are explicitly evaluating whether yours reflects that.
Where Google rewards reasoning under pressure and Meta rewards speed, Apple rewards code that reads like a professional wrote it. Variable naming, function decomposition, error handling, and consistent style are all noted. Think of it as a live code review rather than a problem-solving contest.
The Apple Code Quality Bar
# Apple interviewers compare these two solutions to the same problem.
# Both produce correct output. Only one passes.
# ✗ Correct but fails Apple's bar:
def f(a, b, c):
r = []
for i in range(len(a)):
if a[i] > b: r.append(a[i])
return r[:c] if r else []
# ✓ Same logic — professional quality:
def filter_top_elements(values: list[int], threshold: int, limit: int) -> list[int]:
"""Return the first `limit` elements from `values` exceeding `threshold`."""
if not values:
return []
above_threshold = [v for v in values if v > threshold]
return above_threshold[:limit]
# What Apple explicitly grades:
# · Descriptive function and parameter names (not f, a, b, c)
# · Type hints (signals production awareness)
# · Docstring explaining intent, not mechanics
# · Guard clause for empty input
# · Readable list comprehension vs opaque imperative loop
# · No magic variablesApple’s Problem Profile
- Standard DSA at medium difficulty: arrays, hash maps, trees, graphs.
- Domain-specific depth: iOS roles get Swift memory model, ARC, async/await, actor model; backend gets OS internals, distributed systems primitives.
- Privacy is a first-class concern. “How would you handle this if the data is sensitive?” appears as a follow-up to almost anything.
- Code quality (naming, modularity, error handling) is explicitly noted.
Apple-Specific Preparation
- Research your specific team. Apple recruiters disclose the team early. Use it. Study the domain: memory model, framework APIs, or distributed systems primitives depending on what the team owns.
- Raise your code quality bar in practice. Review every practice solution as if submitting a PR to a senior engineer. Add type hints. Name every variable descriptively. Decompose into helper functions. Handle edge cases explicitly. Do this during practice so it’s automatic under pressure.
- Prepare for privacy follow-ups. After any problem touching user data, have a ready answer: what’s the minimum data surface? What shouldn’t be persisted? What would need encryption?
Apple’s #1 Coding Killer: Treating code quality as an afterthought. Candidates who write single-letter variables, skip edge case handling, and produce correct-but-unreadable code consistently fail Apple’s coding rounds even when their algorithm is sound. Apple’s implicit question in every round: “Would I want to review this person’s code in a PR?” Make sure your code answers yes.
The Universal 5-Phase Coding Protocol
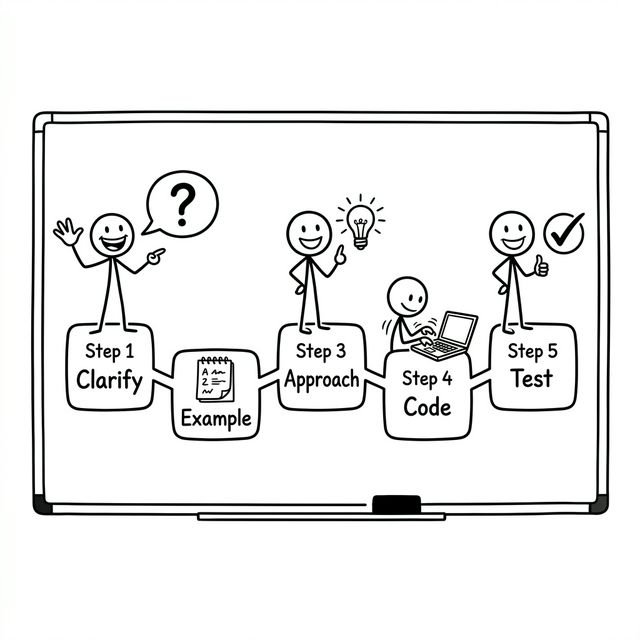
Apply this across all five companies, with the timing adjustments called out below for each.
PHASE 1 — Clarify (2-3 min)
Before writing a single line, ask:
· Input format and type? Constraints on n?
· Can values be negative, duplicate, or null?
· What's returned — index, value, count, boolean?
· Behavior on empty input?
# Do NOT ask questions you could answer by re-reading.
PHASE 2 — Example (1-2 min)
· Work a small example by hand. Write it out.
· Name at least one edge case explicitly.
· Confirm your understanding matches the prompt.
PHASE 3 — Approach (3-5 min)
· State the brute force. Name its complexity.
· Identify the bottleneck and derive the optimization.
· Confirm your approach before disappearing into code.
# Never code for 15 min without the interviewer
# knowing what direction you've chosen.
PHASE 4 — Code (12-18 min, company-dependent)
· Write clean, readable code. Name variables well.
· Narrate as you type — never go silent.
· Catch your own mistakes out loud.
PHASE 5 — Test + Complexity (3-5 min)
· Trace your code on Phase 2's example.
· Run through your edge case explicitly.
· State time AND space complexity — unprompted.
· Note improvements given more time.Company Timing Adjustments: Google: Invest full time in Phase 3; the approach discussion is the GCA signal. Meta: Compress Phases 1-3 to ~4 minutes total; speed is the constraint. Amazon: Hard-cap Phase 4 at 35 minutes to preserve LP discussion time. Netflix & Apple: Extend Phase 3 to cover applied constraints and production implications.
For a more in-depth walkthrough of the 5-phase protocol applied to real problems, see our coding interview preparation guide. If you’re looking for language-specific tips, our Python Data Structures Companion has ready-to-use templates.
The 10 Patterns That Cover ~80% of Problems
The goal of pattern-based preparation is to recognize the applicable pattern from the problem statement before you start coding. Train this explicitly: name the pattern before looking at any solution. Track your classification accuracy. Your mismatches reveal your real weak points.
| Pattern | Core Idea | Trigger Signals | Canonical Problem |
|---|---|---|---|
| Two Pointers | Two indices moving toward/away from each other | sorted array, pair sum, palindrome, partition | 3Sum, Container With Most Water |
| Sliding Window | Expand/shrink a subarray window under a constraint | subarray, substring, contiguous, at most k | Longest Substring Without Repeating Chars |
| BFS | Level-by-level traversal via queue | shortest path, minimum steps, level order | Word Ladder, Binary Tree Level Order |
| DFS / Backtracking | Explore all paths; prune invalid branches | combinations, permutations, subsets, paths | Permutations, Word Search |
| Dynamic Programming | Cache overlapping subproblems; build from base cases | optimal, maximize, minimize, count ways | Coin Change, Word Break |
| Heap / Top-K | Maintain a bounded priority queue | k largest, k smallest, k most frequent | K Closest Points, Merge K Sorted Lists |
| Binary Search | Halve the search space each step | sorted, find boundary, minimum feasible value | Search Rotated Array |
| Monotonic Stack | Stack maintaining monotone order of elements | next greater, next smaller, span, histogram | Largest Rectangle |
| Union-Find (DSU) | Group elements into disjoint sets; detect cycles | connected components, union, group, cycle | Accounts Merge |
| Trie | Prefix tree for efficient string lookups | prefix, autocomplete, starts with, dictionary | Implement Trie |
For an in-depth breakdown of how these patterns map to data structures, see our data structures for coding interviews guide. For a curated problem list organized by pattern, see our Grind 75 guide.
Complexity Reference
Know these reflexively. Practice stating both time and space complexity for every solution you write, not at the end, mid-code. At Google especially, interviewers may interrupt to ask.
| Structure / Algorithm | Time | Space | Note |
|---|---|---|---|
| Array access by index | O(1) | O(1) | |
| Hash map insert / lookup | O(1) avg | O(n) | O(n) worst (collisions) |
| Binary search | O(log n) | O(1) | Requires sorted input |
| Heap insert / extract | O(log n) | O(n) | heapify is O(n) |
| BFS / DFS (graph) | O(V + E) | O(V) | V = vertices, E = edges |
| Sorting (comparison) | O(n log n) | O(1)-O(n) | Timsort best case O(n) |
| Naive nested loop | O(n²) | O(1) | The brute force to beat |
| Recursive DFS (tree) | O(n) | O(h) | h = height; O(n) worst (skewed) |
| DP (memoized) | O(n·m) | O(n·m) | Depends on subproblem count |
| Trie insert / search | O(m) | O(m·n) | m = key length |
| Union-Find (optimized) | O(α(n)) | O(n) | Effectively O(1) amortized |
For the complete operations reference for all core data structures, see our data structures guide.
8-Week Practice Roadmap
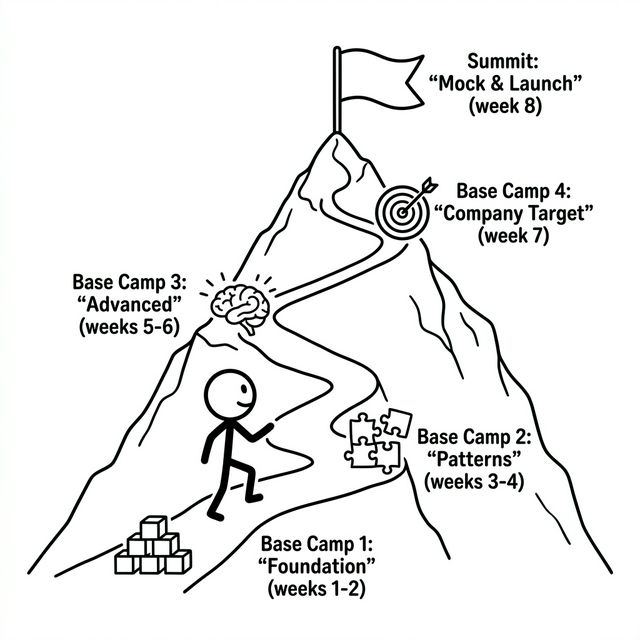
Consistency over intensity. Two focused hours per day outperforms a 10-hour weekend grind. Weeks 1-6 are universal; Week 7 is where you target your specific company.
Weeks 1-2: Foundation
- Internalize all DS operations + complexities using our data structures reference
- 15 easy LC: focus on clean code, not speed
- Set up a plain-text coding environment
- Practice complexity out loud after every problem
Weeks 3-4: Core Patterns
- Two pointers, sliding window: 5 problems each
- BFS / DFS on trees and graphs: 8 problems
- Backtracking: 5 problems
- Start 30-min timed sessions
Weeks 5-6: Advanced Patterns
- Dynamic programming: 10 across types
- Binary search, heap, monotonic stack
- Clean-room rewrites of failed problems
- Begin speaking-aloud practice daily
Week 7: Company Targeting
- Google: Top 30 Google-tagged LC + follow-up generation
- Meta: LC Meta 3-month tag + 2-problem sprints
- Amazon: Debugging drills + OA simulation
- Netflix/Apple: Domain research + applied problems
Week 8: Mock & Stabilize
- Full mocks on Intervu, Pramp, or interviewing.io
- Simulate exact company format
- No new content: reinforce, don’t expand
- Protect sleep and mental readiness
For a more detailed study plan with specific problems mapped to every day, see our complete coding interview preparation guide. The speaking practice is the most neglected and most impactful preparation activity. Most candidates can solve problems but can’t explain them fluidly. For more on why mock interviews matter, see why LeetCode alone isn’t enough.
The 8 In-Interview Coding Killers
These are behavioral failure modes, not knowledge gaps. Capable engineers fail coding rounds because of these.
1. Coding Before Clarifying
Starting to code immediately signals you don’t reason before acting. Two minutes of clarification prevents 20 minutes of solving the wrong problem.
2. Skipping the Brute Force
Even when you know the optimal approach, state the brute force and its complexity first. Skipping it signals you don’t understand why the optimization works.
3. Going Silent
More than 30 seconds of silence reads as stuck with no path forward. Narrate uncertainty out loud. Structured uncertainty is a positive signal; silent uncertainty is a red flag.
4. Not Testing Your Code
Catching your own bug and fixing it out loud is a positive signal. Having the interviewer catch it is a deduction at Google and a missed self-correction signal everywhere else.
5. Forgetting Space Complexity
Every hash map, stack, and memoization array costs space. Practice stating both time and space, every time, for every problem you touch.
6. Poor Variable Naming
Single-letter variables and magic numbers signal you write code for yourself. FAANG interviewers are your future code reviewers. Write code they would approve in a PR. This matters most at Apple but is noted everywhere.
7. Giving Up Instead of Simplifying
If stuck, simplify explicitly: “Let me solve the case without duplicates first, then extend.” A partial working solution with a clear generalization path is always better than a blank canvas.
8. Ignoring the Clock
Fatal at Meta (problem one overrun), costly at Amazon (into LP time), and damaging everywhere. Glance at the time after Phase 3. Know your position relative to your budget before you start coding.
Readiness Benchmark
Check these against actual clock performance, not in theory.
- ☐ I can solve LeetCode medium problems in under 25 minutes while talking through my approach out loud
- ☐ I can identify the applicable pattern from a problem statement before looking at any solution
- ☐ I can state time and space complexity for any solution I write, unprompted, within 30 seconds of finishing
- ☐ I can write clean, readable code in a plain text editor with no autocomplete and no syntax highlighting
- ☐ I can trace through my code manually and catch bugs without running it
- ☐ I have solved at least 3 problems from each major pattern (two pointers, sliding window, BFS, DFS, DP, heap, binary search)
- ☐ I have done at least 5 timed mock interviews simulating the exact format of my target company
- ☐ I can solve two LeetCode medium problems back-to-back in 35 minutes (for Meta targets)
- ☐ I can explain any solved problem clearly in under 2 minutes, from scratch, without notes
- ☐ I have clean-room rewritten at least 10 previously failed problems the next day without notes
The companies are different. Google rewards deliberate reasoning and follow-up depth. Meta rewards speed and two-problem throughput. Amazon has a debugging OA almost nobody prepares for. Netflix cares about applied systems thinking more than abstract puzzles. Apple is grading your code quality as much as your algorithm. Prepare for the company you’re targeting, not for a generic “FAANG.” The candidates who get offers aren’t smarter; they’ve prepared for the right game.
Frequently Asked Questions
How is the FAANG coding interview different from a normal technical interview?
FAANG coding rounds have higher communication expectations than most companies. Beyond correct solutions, interviewers evaluate your reasoning process, your ability to handle follow-up questions, and the quality of your code. Companies like Google use Google Docs (no code execution), and Meta requires solving two problems in 35 minutes. The bar is higher on delivery, not just correctness.
Which FAANG company has the hardest coding interview?
Netflix asks the hardest individual problems (applied, domain-specific, often hard-level), but Meta’s format is the most demanding due to its time constraints (two problems in 35 minutes). Google’s follow-up escalation pattern is uniquely challenging because it pushes you into unfamiliar territory. The “hardest” depends on whether time pressure, problem difficulty, or reasoning depth is your weakness.
How many LeetCode problems should I solve for FAANG?
75-100 problems with deep pattern understanding beats grinding 500 with shallow memorization. Focus on the Grind 75 list for maximum coverage with minimum problems. The right metric is pattern recognition speed, not problem count.
Should I target my preparation for a specific company?
Yes, after building a general foundation. Each company has distinct characteristics worth targeting: Google Docs practice and follow-up handling for Google, speed drills for Meta, debugging practice and LP preparation for Amazon, domain research for Netflix and Apple. Spend the final 1-2 weeks tailoring your preparation.
How important is communication during the coding interview?
At Google, communication weight is rated “Very High”; it’s a primary evaluation dimension, not a nice-to-have. At every FAANG company, a candidate who narrates their reasoning while solving a medium problem outscores one who silently produces a perfect hard solution. Practice talking through problems out loud as rigorously as you practice solving them.
What if I get stuck during a FAANG coding interview?
Getting stuck is normal and expected. Verbalize your thought process: “I’m considering a hash map approach but not sure how to handle duplicates.” Ask for a hint; interviewers provide them intentionally, and using hints well is a positive signal. If fully stuck, simplify the problem: solve it without the hard constraint first, then extend.
Start Practicing Like It’s the Real Interview
The coding round is a learnable skill, not a fixed trait. What separates candidates who get offers from those who don’t is almost never raw intelligence; it’s structured preparation, company-specific targeting, and the discipline to practice communication as rigorously as problem-solving. The code is only half of what’s being evaluated. The reasoning behind it is the other half.
Ready to practice under realistic conditions? Try a mock coding interview on Intervu →
Further reading:
- How to Prepare for a Coding Interview in 2026, the complete roadmap with study plans
- Data Structures for Coding Interviews, deep dive on the 10 structures that matter
- The Grind 75 Pathway, problem list with AI practice links
- Why LeetCode Alone Isn’t Enough, what to practice instead
- Practice Any LeetCode Problem, as a live mock interview